
Le Cloud a apporté son lot de nouveautés: nouveau business model, nouvelle façon de concevoir, déployer et d’opérer les infrastructures et applications, qu’elles soient de type IaaS ou PaaS et a facilité l’introduction du concept DevOps en son sein. D’autres innovations telles que les conteneurs, Serverless ou encore architecture orientée micro-service, ont également apportées de nouvelles façons d’appréhender les applicatifs, que l’on désignerait comme Cloud Native, si un certain nombre de caractéristiques sont appliquées, comme le résume très bien les TWELVE FACTORS, que nous aborderons ici.
L’ensemble de ces innovations introduisent de nouveaux concepts ambitieux comme le DevNoOps ou le DevSecOps, qui annonce la mort certaine à court terme de métiers tels que les administrateurs systèmes, par exemple, dans le sens ou les applications seront « intelligentes » grâce au technologies et concepts que nous allons aborder ici. Le but n’étant pas de détailler ici toutes les technologies existantes d’un point de vue technique, mais de faire un tour d’horizon sur les tendances actuelles et futures et aussi pour s’ouvrir l’esprit à nos métiers de demain (transformation ?) et la façon dans les applications seront conçues…
Nous allons aborder ici un certain nombre de concept et technologies, comme le concept DevOps, l’intégration continue, … afin d’obtenir l’horizon le plus large possible et de se rendre compte à quel point tout bouge rapidement et d’intégrer tout cela dans vos futures réflexions.
1. Intégrer les douzes facteurs d’une application Cloud Native
En premier lieu, si nous désirons qu’une application soit Cloud Native, il convient de respecter un certain nombre de critères, selon TEWLVE FACTORS, qui reprends l’ensemble des concepts et technologies abordées ici:
- Utilisent un format déclaratif pour l’automatisation des installations
- Ont un contrat clair avec l’OS sous-jacent et qui offrent une portabilité maximale pour l’exécution sur différents environnements
- Sont adaptées à un déploiement sur des plateformes cloud
- Minimisent la divergence entre développement et production et permettent un déploiement continu pour un maximum d’agilité
- Peuvent monter en charge sans changement majeur d’outillage, d’architecture ou de pratique de développement
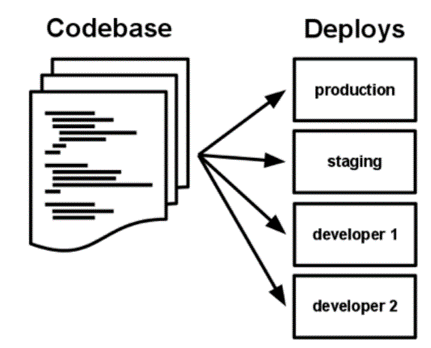
| 1. BASE DE CODE
L’application doit être maintenue dans un système de contrôle de version (Git..). Un codebase = 1 Repository 2. DEPENDANCE Isoler et déclarer de manière explicite les dépendances. L’application ne doit pas se reposer sur l’existence implicite de quelconques outils systèmes 3. CONFIGURATION Séparation stricte de la configuration et du code. La configuration peut changer entre différents déploiements, pas le code ! Stocker la configuration à l’extérieur de l’application. |
 |
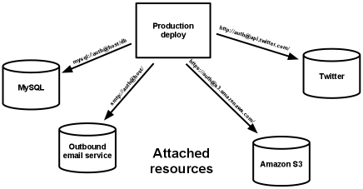
| 4. Service externe
Le code d’une application ne fait pas de différence entre le local et un service tiers. Pour l’application ce sont toutes des ressources attachées (backing services) |
 |
| 5. Build, Release, Run
Séparer de manière stricte les étapes de Build et de Run |
 |
| 6. PROCESSUS
Les processus sont sans état (stateless) et ne se partagent rien. Les données persistantes doivent être stockées dans un backing service (ex: BDD) 7. ASSOCIATION DE PORTS L’application doit être self-contained. La gestion des ports est gérée par la plateforme cloud 8. CONCURRENCE Chaque type de travail de l’application est associé à un type de processus. La montée en charge s’effectue en démultipliant les instances 9. JETABLE Augmenter la robustesse avec des démarrages rapides et des arrêts propres. Les processus doivent être robustes à une mort subite (jetables) 10. PARITE DEV/PROD Garder les environnements de développement, staging et de production les plus similaires possible. L’application doit être conçue pour du déploiement continu en limitant les écarts entre développement et production. Eviter d’utiliser des backing services différents entre développement et production 11. LOGS Traiter les journaux (logs) comme un flux d’évènements. L’application ne doit pas s’occuper du routage ou du stockage du flux généré en sortie 12. PROCESSUS D’ADMINISTRATION Les tâches de maintenance/administration sont versionnées avec le code et sont mises à jour avec les releases. Les tâches sont entièrement automatisées |
|
2. L’approche DevOps
Dans le cadre de la mise en production d’une application en passant par la conception, le test, … (la chaîne) il existe plusieurs approches, classique (Waterfall par exemple) et DevOps (Agile, …) qui incluent les OPS (Ingénieurs systèmes, architectes, …) et les DEV (développeurs, Architectes logiciels, …).
Dans une approche classique, les équipes sont le plus souvent compartimentées, et ne pensent qu’à leurs tâches, en bref: les DEV produisent du code, les évolutions fonctionnelles, … et les OPS mettent à disposition les infrastructures sans tenir compte des évolutions logicielles mais plutôt en se concentrant sur le SLA du service ainsi que la performance associée.
Dans une approche de type DevOps, l’ensemble des acteurs, soit les DEV et les OPS se répartissent les responsabilités et sont tous impliqués dans le chaîne de mise en production d’une application. Le concept DevNoOps, les nouvelles technologies permettront de s’affranchir des OPS dans le sens où le code de l’infrastructure ne deviendra plus q’une variable dans la chaîne. Nous y reviendrons plus tard.
2.1. Comprendre la différence entre la livraison, le déploiement et l’intégration continue CI/CD
Les acronymes CI et CD sont couramment utilisés lorsque l’on parle de DevOps:
- CI: intégration continue, une pratique qui vise à faciliter la préparation d’une version
- CD: une livraison continue ou un déploiement continu, et bien que ces deux pratiques aient beaucoup en commun, elles ont également une différence significative que nous allons détailler
2.1.1. Intégration continue
Les développeurs pratiquant une intégration continue fusionnent leurs modifications dans la branche principale aussi souvent que possible. Les modifications du développeur sont validées en créant une génération et en exécutant des tests automatisés par rapport à la génération. L’intégration continue met l’accent sur l’automatisation des tests pour vérifier que l’application n’est pas interrompue chaque fois que de nouveaux commits sont intégrés dans la branche principale.
2.1.2. Livraison continue
La livraison continue est une extension de l’intégration continue pour permettre de générer rapidement de nouveaux changements. Cela signifie qu’en plus d’avoir automatisé les tests, vous avez également automatisé votre processus de publication et vous pouvez déployer votre application à tout moment en cliquant sur un bouton.
2.1.3. Déploiement continu
Le déploiement continu va plus loin que la livraison continue. Grâce à cette pratique, chaque modification apportée à toutes les étapes de votre pipeline de production est transmise aux utilisateurs. Il n’y a pas d’intervention humaine, et seul un test échoué empêchera le déploiement d’un nouveau changement dans la production.
Quelques outils appartenant à une chaîne DevOps:
- Code & Commit: Git, Github, Visual Studio, Eclipse, …
- Build & Config: Docker, Chef, SaltStack, Puppet, Ansible, …
- Scan & Test: Sonar, BlazeMeter, Gerrit, …
- Release: uDeploy, Serena, CollbaNet, XL Release, …
- Deploy: Kubernetes, Azure, VMware, OpenStack, …
Un schéma est toujours utile pour illustrer les dires précédents…

Selon un sondage effectué en 2016 par Puppet auprès de 4 600 professionnels de l’informatique, les services informatiques disposant d’un flux de travail DevOps ont déployé un applicatif 200 fois plus fréquemment. De plus, ils ont récupéré 24 fois plus vite et ont eu trois fois moins de taux de défaillance. Simultanément, ces entreprises consacrent 50% de temps en moins aux problèmes de sécurité et 22% de temps en moins au travail non planifié.
3. Les Conteneurs ou architecture orientée micro-service
En exploitant les conteneurs dans le cadre de votre stratégie, vous pouvez gagner en efficacité, en souplesse et améliorer la sécurité des applications. Les conteneurs permettent de facilement packager, déployer et exécuter n’importe quelle application en tant que conteneur léger, portable et autonome, pouvant s’exécuter pratiquement n’importe où, en isolant le code dans un seul conteneur, ce qui facilite sa modification et sa mise à jour.
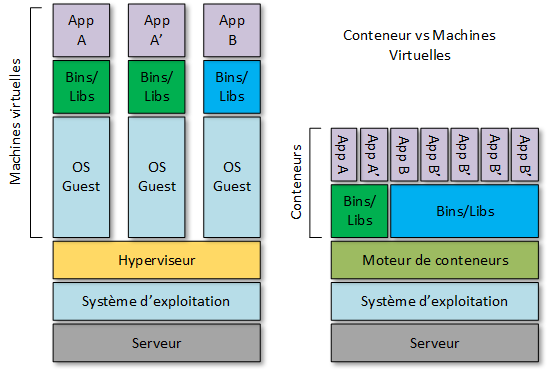
Docker, par exemple, est construit sur LXC (LinuX Container). Comme avec toute technologie de conteneur, il dispose de son propre système de fichiers, de son stockage, de son processeur, de sa mémoire vive, etc… La principale différence entre les conteneurs et les machines virtuelles réside dans le fait que l’hyperviseur extrait un périphérique entier, mais que les conteneurs ne font que présenter le noyau (kernel) du système d’exploitation.
Les applications actuelles dites « classiques » ou legacy s’exécutent sur un système d’exploitation. Le système d’exploitation peut être exécuté sur un hôte Bare Metal ou sur une machine virtuelle. Les conteneurs fournissent la virtualisation du système d’exploitation sur les hôtes Windows et Linux. Plusieurs conteneurs indépendants peuvent être exécutés au sein d’une même instance Linux ou Windows, évitant la surcharge liée au démarrage et à la maintenance des machines virtuelles.
Les conteneurs vous permettent de conditionner l’application avec son environnement d’exécution complet, soit tous les fichiers nécessaires à son exécution. L’image de conteneur contient toutes les dépendances de l’application, elle est portable et cohérente au fur et à mesure qu’elle passe du développement au test et enfin à la production.
| Fonctionnalité | Conteneur | VM |
| Définition | Virtualisation d’OS | Virtualisation de serveur |
| OS | Partage OS hôte | Chaque VM a son propre OS |
| Taille | Mo | Go |
| Démarrage | secondes | minutes |
| Kernel | Partagé avec l’hôte | Chaque VM a son propre Kernel |
Les conteneurs permettent de configurer des environnements de développement locaux qui s’exécutent exactement comme un serveur de production, exécuter plusieurs environnements de développement à partir du même hôte avec un logiciel, des systèmes d’exploitation et des configurations uniques, tester des projets sur de nouveaux ou différents serveurs, et permettre à quiconque de travailler sur le même projet avec les mêmes paramètres, quel que soit l’environnement hôte.
Les entreprises utilisent les conteneurs pour réduire leur dépendance aux technologies de virtualisation commerciales telles que vSphere de VMware, il en résulte une réduction des coûts tout en réduisant l’utilisation de technologies de virtualisation classique.
Selon une étude de Diamanti menées auprès de 576 responsables informatique datant de 2018, 44% des sondés prévoient de remplacer des machines virtuelles par des conteneurs. Plus de la moitié (55%) consacrent plus de 100 000 dollars par an aux droits de licence VMware , et plus du tiers (34%) dépensent plus de 250 000 dollars par an en droits de licence VMware. Près de la moitié des responsables informatiques interrogés prévoient de déployer des conteneurs en production, tandis que 12% d’autres déclarent déjà en avoir.
En termes de part de marché, les technologies de conteneurs les plus largement adoptées ne sont pas étonnant: Docker à 52% et Kubernetes en tant d’orchestrateur à 30%. Un point intéressant révèle que 71% des personnes interrogées ont déployées des conteneurs dans une machine virtuelle, ce qui signifie que les machines virtuelles ne vont pas disparaître, mais la tendance est de réduire les coûts de licence. Voici trois caractéristiques principales qui caractérisent les conteneurs:
Efficacité
Prenons le plus connu, Docker, une plate-forme de conteneurs qui possède des nombreuses références à son actif. Avec Azure, la consommation a lieu sur le conteneur plutôt que sur l’application ou la machine virtuelle et donc les coûts Azure sont moindres, tout comme les dépenses de maintenance et de licence. Je prends l’exemple de mon blog où j’ai plus que divisé par deux les coûts de son hébergement en passant d’une VM à une solution de conteneur, en l’occurrence Docker.
Les plates-formes de conteneurs sont capables de générer un impact mesurable à tout point de vue grâce à une densité d’applications bien supérieure à celle des machines virtuelles, sans sacrifier les performances des applications et tout en réduisant le temps nécessaire pour effectuer des tâches courantes, en accélérant le développement et le déploiement en s’intégrant parfaitement dans une chaîne de déploiement continu DevOps.
Flexibilité
Avec une plate-forme de conteneurs véritablement agnostique, les entreprises bénéficient d’une réelle flexibilité en libérant les applications de leur environnement et de pouvoir les héberger en fonction des besoins. De plus, les conteneurs offrent une véritable portabilité car ils sont basés sur des normes ouvertes et s’exécutent sur toute infrastructure (Cloud, virtuelle, …). Ainsi, les entreprises n’ont plus besoin de s’engager à long terme sur leur infrastructure.
Sécurité
Les plates-formes de conteneur isolent les applications de l’infrastructure, ainsi que d’autres applications, ce qui réduit la surface exposée. Les espaces de noms du noyau Linux isolent la vue de l’application d’un environnement d’exploitation, y compris les arborescences de processus, le réseau, les ID utilisateur et les systèmes de fichiers montés, tandis que les groupes de contrôle du noyau limitent les ressources, notamment le processeur, la mémoire, …
Avantages
- Les conteneurs sont plus portables que les machines virtuelles et peuvent être déployés dans les Clouds publics, les Clouds privés et les Datacenters traditionnels
- Rationalisation du cycle de développement des logiciels sur les différents environnements, car il n’existe plus d’adhérence comme nous avons pu en connaitre dans des architecture traditionnelles
- Les tests et le suivi des bogues deviennent également moins compliqués car il n’y a pas de différence entre les environnements
- Les conteneurs sont légers et peuvent démarrer en quelques secondes
- Ils partagent un système d’exploitation commun, ce qui réduit les coûts, moins de serveurs (car consomment moins de ressources), moins d’OPS, …
Inconvénients
- Les conteneurs ont un domaine de défaillance plus élevé lorsqu’ils partagent le même système d’exploitation hôte
- D’où l’importance d’un orchestrateur !
- Les conteneurs sont moins sécurisés que les machines virtuelles. Les conteneurs partagent le noyau et les autres composants du système d’exploitation hôte et disposent d’un accès root. S’il existe une vulnérabilité dans le noyau, cela peut compromettre la sécurité des conteneurs (en théorie car aucun exploit n’est connu à ce jour)
- L’implémentation de la mise en réseau et du stockage des conteneurs reste un problème par rapport aux machines virtuelles
- Toujours l’importance d’un orchestrateur et d’un SDN
Les architectures micro-services permettent des déploiements plus petits, plus fréquents et plus nombreux mais ils doivent être fortement découplés, distribués et élastiques. Ce qui induit une multiplication des conteneurs (Cattle) car une application pensée micro-services est découpée en de multiples services/composants qui sont faciles à updater, débugger, etc… Prenons l’exemple d’un site marchand, qui serait composé de:
- Module WEB
- 1 micro-service WEB Frontend
- Module produits:
- 1 micro-service BDD de produits
- Module commande:
- 1 micro-service API
- 1 micro-service BDD de produits
- Module expédition:
- 1 micro service CosmoDB
- …
Cette architecture permet de scinder les différents métiers/services les uns étant indépendant des autres mais en contrepartie, l’orchestrateur sera révélera indispensable pour gérer cet ensemble de Cattle…
3.1. L’orchestration des conteneurs
Comme tout élément de l’infrastructure informatique, les conteneurs doivent être surveillés et contrôlés. La courte durée de vie des conteneurs et leur densité accrue ont des implications importantes dans la surveillance des infrastructures. qui doivent être surveillés individuellement. La réponse réside dans les outils d’orchestration. Ceux-ci surveillent, gèrent le clustering et la planification des conteneurs.
Il existe trois solutions majeures d’orchestration de conteneurs dans le cloud: Docker Swarm, Kubernetes (K8s pour les intimes) et Mesosphere, mais Kubernetes est de loin le programme d’orchestration le plus répandu (anciennement BORG qui était utilisé par google pour ses propres besoins pour gérer ses charges de travail à l’échelle mondiale et sur des dizaines de milliers de nœuds).
Il y a quelques temps, Mesosphere a intégré Kubernetes, en l’intégrant à DC/OS. Docker intègre Kubernetes dans sa plateforme Docker, tout comme Microsoft avec Azure… Les utilisateurs peuvent choisir d’utiliser Kubernetes et / ou Docker Swarm pour l’orchestration, mais il convient de noter que 54% des entreprises Fortune 100 utilisent Kubernetes.
La tâche principale de l’orchestrateur consiste à maintenir l’état de fonctionnement des applications dans son giron, il gère un cluster de nœuds faisant référence à des serveurs physiques ou virtuels. Voici trois fonctions essentielles:
Continuité: lorsqu’une application est composée de composants granulaires, il devient beaucoup plus facile de faire évoluer cette application en mettant à jour et en améliorant ces composants individuellement. Les améliorations apportées aux applications ne sont plus mises en œuvre dans le cadre de révisions massives – ce qui, le plus souvent, a un impact négatif sur leur utilisation
Résilience – Avec Kubernetes, celui-ci gère les répliques actives des groupes de conteneurs, appelées ensembles de réplicas, dans le but précis de maintenir la disponibilité et la réactivité en cas d’échec d’un regroupement de conteneurs ou de conteneurs (ce que Kubernetes appelle un pod). Cela signifie qu’un Datacenter n’a pas besoin de répliquer l’application entièrement pour basculer vers l’application secondaire en cas de défaillance. En fait, une pluralité de modules dans un jeu de réplicas s’exécutent à un moment donné, et le travail de l’orchestrateur consiste à maintenir cette pluralité tout au long de la durée de vie de l’application.
Évolutivité – Le grand avantage pour les organisations qui orchestrent les charges de travail distribuées est la capacité intégrée des charges de travail de se multiplier dans le système, afin de les redimensionner selon des règles définies.
4. Infrastructure as Code ou IaC
Il convient de distinguer la différence entre l’orchestration de la configuration et le management de la configuration, le premier inclut des outils comme Terraform qui automatise le déploiement, tandis que le seconde inclut d’autres outils comme Chef ou Puppet qui aide à configurer les systèmes (création de compte de services, …) et applications (installation de SQL Server, …) sur des infrastructures préalablement déployées avec Terraform, par exemple, le tout via du code bien sûr. Bref, on pourrait presque parler de template dynamique s’inscrivant parfaitement dans une logique DevOps, car on va gérer la gestion de la configuration dans le pipeline d’intégration de de livraison continue.
Infrastructure as Code repose sur des outils offrant une abstraction haut niveau des ressources d’infrastructure, offrant une bien meilleure lecture qu’un fichier JSON (pourrait ton parler de la mort de la documentation ? à condition de bien commenter son code), comme Terraform. Faire le choix de l’outil Terraform se révélera être judicieux comme nous parle Microsoft qui investit massivement dans cette technologie. Celui-ci utilise une syntaxe déclarative qui définit un état final souhaité au lieu d’une syntaxe impérative qui décrit une série d’actions pour arriver à une finalité. Comparons les syntaxes dans le cadre de la création d’un serveur virtuel:
- Impératif: créer du stockage => créer du réseau => créer le VM => installer l’OS => ….
- Déclaratif: je veux un serveur Windows avec 4Gb de RAM, 60 Gb HDD, 1 NIC et 2 cores vCPU
La séparation de la configuration du code, et de sa variabilisation permettront de maximiser l’usage du template pour de multiples environnements, par exemple (1 template servira à 4 environnements). Le code devient ainsi un build, qui est combiné avec une configuration pour créer une version.
L’outil Terraform offre la possibilité de tester ses tempates avant déploiement, des backends distants pour travailler en équipe, compatible AWS, Azure, des workspaces, … Il permet de fournir une infrastructure reproductible, standardisée et extensible et est l’une des premières étapes de l’intégration des pratiques DevOps au sein d’une entreprise.
5. Serverless (application sans serveur)
Il ressort principalement 3 uses cases concernant le ServerLess : des APIs « simple » et scalable, l’automation, et le Data Processing. Les avantages sont multiples: configuration minimale, support multi langages (python, NodeJS, Java, Powershell, …), Cloud agnostic, support de l’ALM et le streaming des logs. Quelques comparaisons:
- Serverless vs Conteneur: Docker empaquette le logiciel dans des unités standardisées (conteneurs) pour faciliter la gestion des dépendances des applications et simplifier la gestion du serveur tandis que le Serverless sont essentiellement des conteneurs éphémères, où le démarrage / arrêt est géré automatiquement. Les applications sans serveur déployées sont fondamentalement sans administration et évoluent automatiquement avec la demande, ce qui évite de gérer des instances de serveur et centrées sur le CODE avec une tarification adaptée (paiement à l’exécution du code et non par instance)
- Serverless vs Terraform: Terraform est un outil de déploiement Cloud qui décrit l’infrastructure en tant que code et se déploie simultanément sur plusieurs Cloud tandis que Serverless facilite le développement et le déploiement d’applications sans serveur (code). Ils peuvent donc travailler de concert !
On entends beaucoup de choses sur le Serverless, que c’est le NoOps par excellence, que cela va induire un « DEPRECATED » sur les conteneurs, etc… On va plutôt dire que c’est du « Cloud Native » par excellence et que la réalité est que tout composant a besoin d’OPS même ceux sur lesquels vous avez peu de contrôle.
Il ne faut pas confondre Serverless et NoOps. Si on prend le mot Ops (Opérations) cela ne signifie pas uniquement des opérations d’administration des systèmes. Cela signifie également à minima le suivi, le déploiement, la sécurité, la gestion du réseau, … Mais la jeunesse de la technologie induisent d’autres contraintes opérationnelles comme le debug, par exemple.
La technologie Serverless se limite à un déclenchement d’une exécution de code (fonction) selon un besoin (événement), sans qu’un serveur doive fonctionner en continu mais Serverless ne saurait se substituer à un système CRM, ou a des besoins de contrôle que peuvent offrir un conteneur ou une VM, par exemple. Point bloquant important, le Serverless est locké par Cloud Providers qui utilisent leurs propres services, API, … Une portabilité n’est donc pas possible et nécessite une réécriture du code de la fonction.
Autre point négatif, il faut un certain temps pour qu’une plateforme FaaS initialise une instance d’une fonction avant chaque événement. Cette latence de démarrage peut varier considérablement, même pour une fonction spécifique, en fonction d’un grand nombre de facteurs, et peut aller de quelques millisecondes à plusieurs secondes. Microsoft en parle d’ailleurs ici.
Ainsi en adoptant Serverless, au lieu d’écrire des applications avec plusieurs points de terminaison, le développeur écrit simplement des gestionnaires d’événements et mappe les déclencheurs aux gestionnaires avec l’API de la plateforme. Contrairement aux plates-formes d’applications, les plates-formes de fonctions intègrent de manière transparente la mise à l’échelle automatique basée sur la charge, car elles contrôlent tous les points d’entrée et le multiplexage.
Pour résumer, la bonne définition serait la suivante:
Serverless est un modèle d’exécution de code de Cloud Computing dans lequel le fournisseur de Cloud gère de manière granulaire l’exécution de code à l’invocation de fonction individuelle par rapport au serveur d’applications traditionnel
Voici une application typique Serverless, un client qui va interroger un utilisateur présent dans Office 365 pour l’inscrire dans une base de données SQL.
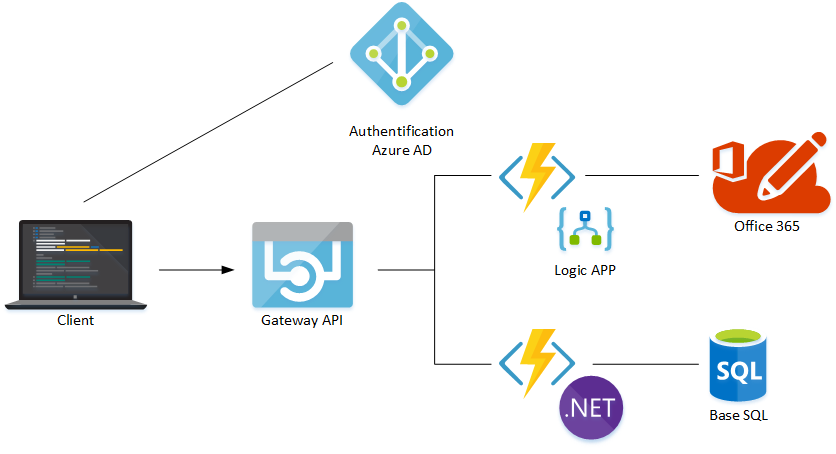
| Contrôle & Responsabilité | |||
| IaaS | PaaS | FaaS | Saas |
| Configuration de l’application Application Configuration du serveur Système d’exploitation Antivirus Réseau Patching …. |
Configuration de l’application Application Configuration du serveur |
Configuration de l’application Application |
Configuration de l’application |
5.1. OpenFaaS, une approche intéréssante
OpenFaaS est un framework, qui s’intègre parfaitement à Swarm et K8s, qui permet de transformer n’importe quel conteneur Docker en fonction supportant plusieurs langages (C#, Java, PHP, Go, Rust, Javascript, …). Il permet une supervision plus poussée et permet aussi de prendre en charge l’élasticité.
6. L’Application Management Performance (APM) dans une chaîne NoOps
L’approche Shift-Left dans un mode AGILE permet de garantir la qualité du code dans le but de le déployer en production avec un niveau de qualité élevé. De l’autre côté, nous avons l’approche Shift-Right qui agit sur une application en production où les besoins de tests sont importants tout comme la supervision applicative au sens large. Dans un modèle AGILE, les besoins de tests (test unitaire, UAT, performance, monitoring, …) sont indispensables, c’est là qu’intervient l’APM !
Les APM modernes (orientés Cloud et/ou DevOps) permettent d’améliorer la performance, réduire le temps de résolution d’incident(s), d’anticiper les problèmes, d’identifier les « roots causes », d’améliorer l’expérience utilisateur, les tests, … Les APM peuvent fournir des analyses prédictives pour identifier les anomalies et alerter les équipes DevOps avant que le service soit impacté (Shift-Right). Plus la solution APM sera capable d’identifier un problème rapidement, plus vite les équipes DevOps pourront mitiger l’impact. Ce sondage de IBM nous démontre bien les attentes des entreprises vis-à-vis d’une solution APM.
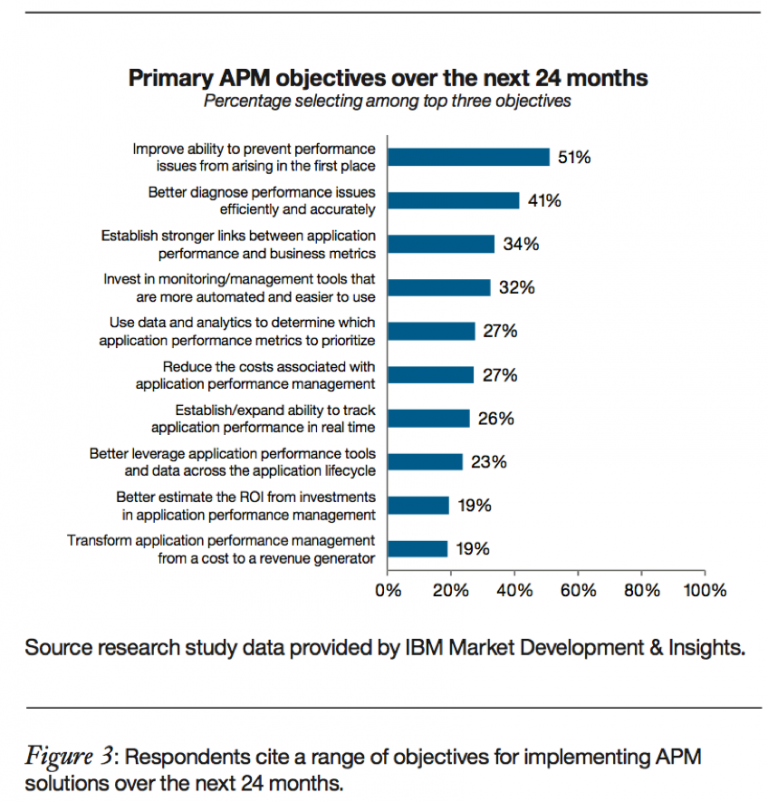
Selon Enterprise Management Associates (EMA), 70% des entreprises utilisent encore un ensemble de processus de débogage manuels et cela constitue un goulot d’étranglement important dans leur pipeline de distribution continue. Le rapport «État des DevOps 2017» de Puppet indique que les entreprises adoptant un APM sont consacrent 22% moins de temps aux travaux de reprise ou aux arrêts non planifiés, les déploiements sont 46 fois plus fréquents et les délais de réparation 96 fois plus rapides.
Par exemple, Microsoft Azure Application Insights surveille les applications .NET, Java et Node.js avec des outils de requête et de rapport avancés et personnalisables. Il détecte automatiquement les anomalies de performance et inclut des outils d’analyse pour aider à diagnostiquer les problèmes et à comprendre ce que les utilisateurs font réellement avec l’application. Il est conçu pour aider à améliorer continuellement les performances et l’expérience. Il s’intégrera naturellement à votre processus DevOps et est ouvert à d’autres outils de développement.
- ReSharper for Visual Studio est une extension Visual Studio qui analyse le code source écrit ou en cours d’exécution, afin de détecter les goulots d’étranglement potentiels, les problèmes de pile ou d’autres problèmes de performances spécifiques au code
- Poussons un plus loin la réflexion en parlant de Self Healing ou Auto Remediation et d’intelligence artificielle. L’APM de DynaTrace se base sur des algorithmes d’intelligence artificielle (AI) pour analyser les anomalies de façon encore plus proactive
Lorsque nous parlons de Self Healing ou Auto Remediation, on parle d’un système capable de percevoir qu’il ne fonctionne pas correctement et, sans intervention humaine, de faire les ajustements nécessaires pour rétablir son fonctionnement normal. On pourrait presque parler ici de « Autonomic Computing », mais ce terme sous-entends en plus que l’application est auto-configurable, auto-optimisée et auto-protégée, mais pas que et cela peut faire rêver ou faire peur du genre Skynet dans Terminator… Pour qu’une application puisse s’auto-réparer, elle doit: détecter les échecs, répondre aux échecs et enregistrer et surveiller les défaillances pour obtenir des informations opérationnelles.
7. L’approche NoOps
Une approche NoOps signifie l’ automatisation du déploiement, de la surveillance et de la gestion des applications. NoOps peut s’inscrire essentiellement dans du PaaS mais pas seulement, on pourrait décorréler le NoOps de l’approche DevOps pour réduire les opérations d’exploitations telles que la remédiation basée sur de l’IA, par exemple. Certains diront que NoOps est un DevOps réussi… On pourrait aussi avoir une approche uniquement NoOps sans DevOps, non ? Il faut garder à l’esprit d’avoir comme cible une transition totalement automatisée entre le développement et l’exploitation.
NoOps est très orienté Cloud par nature et non au Datacenter traditionnel, car dans ces derniers on aura toujours des tâches « bas niveau » comme le provisionning de serveur physique, switches réseaux, stockage, … Il faut faire abstraction de ces éléments, les conteneurs abordés plus haut sont LA réponse pour du NoOps (mais DevOps aussi).
La promesse NoOps, c’est une infrastructure qui a atteint un tel niveau d’automatisation qu’aucune équipe OPS n’est nécessaire pour l’administrer. En bref, pour que NoOps soit réellement employé, les développeurs ne doivent pas tenir compte des aspects liées aux ressources d’infrastructure. Le PaaS ne serait t’il pas NoOps par définition ? On serait tenté de répondre par l’affirmative pour le cas de base de données comme SQL Azure, par exemple.
7.1 Vous avez dit DevSecOps ???
On parle ici de « Secure by design », DevSecOps consiste à prendre en compte dans la démarche globale DevOps dès le début, l’intégration des équipes sécurité dans ce dispositif pour permettre de traiter le volume plus important de MEP (mise en production), pour prévenir et corriger plus facilement et rapidement des problèmes de sécurité, d’intégrer les contraintes sécurité client, …
Un certain nombre d’aspects liés à la sécurité peuvent être intégrés et automatisés dans la chaîne CI/CD DevOps comme la signature de code, test unitaires, intégration dans des Runtime Application Self Protection (RASP), comme celui de Signal Sciences, ou encore paramétrer le WAF (Web Application Firewall) en mode apprentissage, … dans le but, à minima de couvrir les problèmes de sécurité OWASP TOP10.
8. Pour Conclure
Les opérations restent essentielles dans toute démarche DevOps mais le métier se transforme: les éléments serveurs, réseaux, etc doivent approcher une méthode Infra as Code, un administrateur ne provisionnera plus à la main une VM mais un docker ou une VM « Térraformée » et « Puppetisée » qui s’intègre dans une chaîne DevOps.
NoOps ne signifie pas forcément plus d’opérations, mais plutôt d’intégrer By Design toutes les méthodologies et technologies abordées ici pour pousser l’automatisation au maximum en vue de limiter, voir faire disparaître les interventions manuelles/humaines sans ou peu de valeur ajoutée. Je parlais de la disparition de certains métiers, oui et non, ceux-ci vont devoir évoluer vers des profils d’architectes ou de spécialistes Cloud pour penser et mettre en oeuvre les architectures de demain.
A titre d’exemple, les Datacenters Azure, qui sont énormes ne sont maintenus que par une poignée de personnes, je pense que l’on peut parler ici de NoOps mais dans l’esprit « infrastructure management »… Mais bien entendu, nous ne sommes pas tous des GAFAM mais certains éléments abordés ici peuvent se mettre facilement en place comme l’Infra as Code et vous apportera des apports indéniables et mesurables rapidement.
Pour conclure, les technologies abordées comme le Serverless ou architecture micro-services, l’assimilation des TWELVES FACTORS dans les réflexions, une approche de développement moderne AGILE ou DevOps et l’intégration d’un APM vous permettront à coup sûr de tendre vers le NoOps. Mais quoiqu’il en soit, NoOps est encore très jeune dans son approche, et il y aura toujours besoin des OPS pour maintenir les architectures et les infrastructures, à minima pour les superviser.

