Les entreprises doivent faire face à des applications qui doivent être disponibles 24/7, qu’elles soient hébergées dans un datacenter, accédées via des clients nomades ou depuis des sites distants, …. Bien entendu, il faut également gérer l’augmentation des volumes de données ! De nos jours, de plus en plus d’applications sont/deviennent critiques, ainsi, il n’est pas rare de constater dans une entreprise que la moitié des applications (voir plus) sont indispensables ! Celles-ci doivent donc être intégrés dans le cadre d’un PCA ou PRA, ce qui sous-entends une continuité applicative ET des données !
Voici donc quelques éléments techniques et fonctionnels relatifs à la réplication.
Dans le cadre de PRA, les sauvegardes sont encore couramment utilisées, mais restent contraintes pas des limites géographiques. Les temps de reprise peuvent être considérablement allongés, alors le choix d’avoir un site de secours d’une distance assez faible de celui de production est réalisé, mais ce choix géographique ne prends pas en compte d’éventuelles catastrophes naturelles, comme des tremblements de terre, etc…. De plus, certaines entreprises doivent respecter des conformités HIPAA, Sarbanes-Oxley …. Les solutions de type « Cloud » (attention si vous hébergez vos données chez une société Américaine, la loi Patriotic Act peut potentiellement être dangereuse pour la confidentialité de vos données !) et de virtualisation apportent des réponses concrètes ! En effet, la virtualisation de serveurs ne sont que de « simples » fichiers à manipuler, sauvegardable comme un simple fichier WORD, ou presque mais ce n’est pas l’objet du thème abordé ici.
Pour palier aux sauvegardes et leurs contraintes associées, une réplication peut être déployée de façon synchrone ou asynchrone, mais cela alourdit beaucoup le trafic WAN. Il existe des appliances/solutions appelées accélérateurs WAN qui permettent d’optimiser de façon incroyable le trafic généré sur les WAN, ce qui facilité grandement le déploiement de PCA/PRA.
Il convient d’avoir à l’esprit qu’une réplication n’inclut pas (forcément) des notions de reprise/bascule automatique, et n’est pas une sauvegarde ! En effet, une erreur faite à la source sera répliquée vers les cibles ! Une réplication a pour seule fonction de répliquer les données d’un point vers un autre, en s’assurant bien entendu, que celle-ci soit cohérente d’un point de vue données. Les solutions de réplications sont nombreuses sur le marché EMC SRDF/A, Hitachi True Copy, Netapp SnapMirror, Dell Auto-Replication, etc… pour les données et VMWARE SRM, Veeam Backup & Replication, Platespin Protect, vReplicator, etc… pour les serveurs.
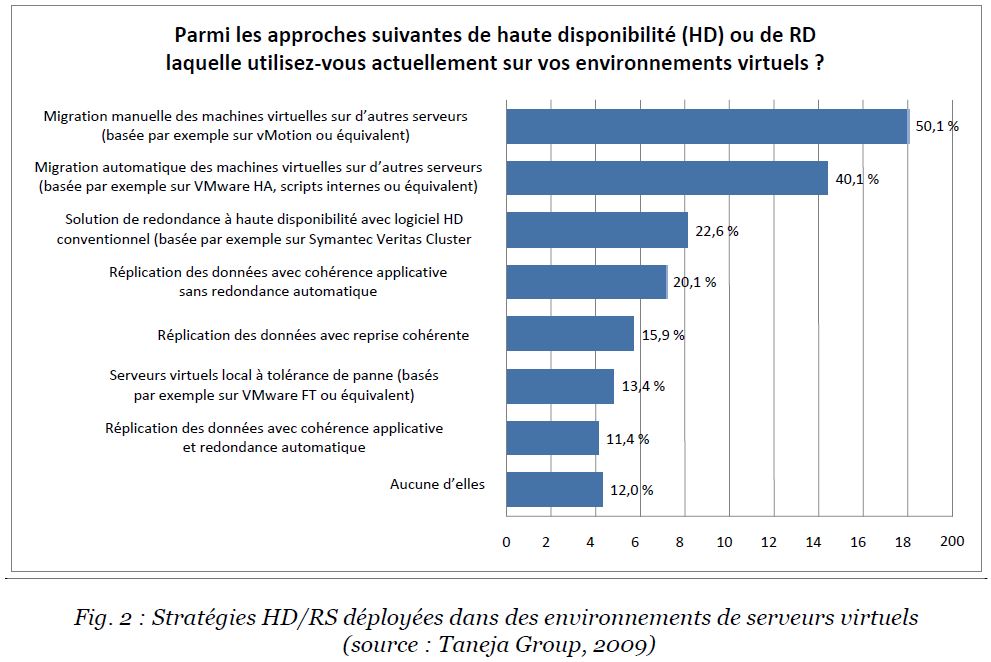
Cette étude menée en 2009 (donc pas si lointaine que cela) montre que les moyens mis en oeuvre sont assez rudimentaires… On est loin d’une disponibilité des applications et des données efficaces: la réplication est employée à hauteur de 20% des serveurs virtualisés !
Plusieurs types de protection et de disponibilité de services: High Availability, Business Continuity, Disaster Recovery. HA – haute disponibilité – représente les moyens locaux: disques durs en RAID, carte réseaux double ports, …. BC – continuité d’activité – fait appel à des notions de clustering (CSV, …) de synchronisation de baie de stockage, VMware HA en local ou sur une distance relativement courte (limite d’une fibre optique, par exemple). DR, ou reprise après sinistre, s’opère la plupart du temps à une échelle WIDE (réseau étendu WAN) de façon asynchrone et demeure complexe à mettre en oeuvre du fait que les paramètres réseaux diffèrent (DNS, …), bande passante relativement faible, appréhender la bascule (failover / failback), …
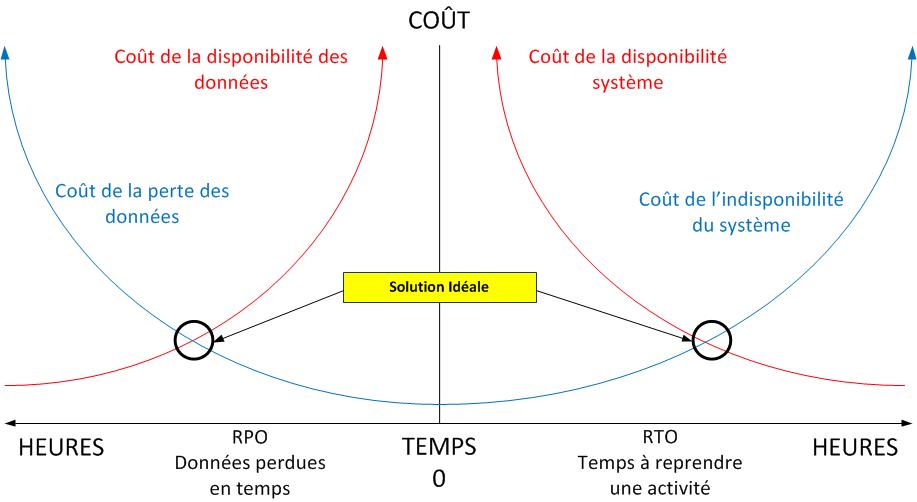
Nous l’aurons bien compris, la qualité nos liaisons WAN sera une critère déterminant pour la mise en oeuvre de PCA/PRA. Ces PCA/PRA doivent tenir compte de notions de RPO et RTO. Le schéma ci-dessous montre comment déterminer son plan, la situation idéale est le résultat du recoupement des coûts associés à la mise en oeuvre un PCA/PRA et des coûts liés à une perte de données et/ou d’indisponibilité. Si le coût d’une solution type VMware SRM (Site Recovery Manager) permettant une haute disponibilité du système coûte 100.000 € et que l’indisponibilité du système mettrait 40 salariés au chômage technique d’un coût de 50.000 € par heure, votre objectif doit être de reprendre en 2 heures. Voici un peu l’esprit du schéma présenté ci-dessous.
L’organisme SNIA, Storage Networking Industry Association, nous gratifie également d’un joli tableau prenant en compte les TIER, si vous désirez vous lancez dans l’hébergement d’application ou pour respecter les standards.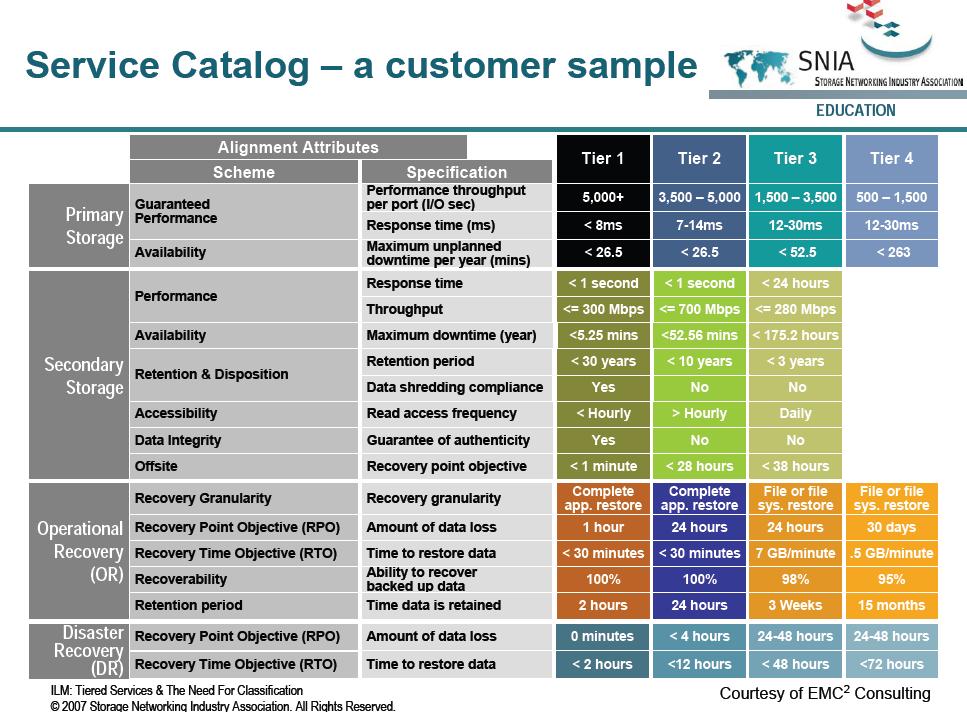
Bien entendu, les niveaux de disponibilité sont liés à la fréquence et à la rapidité des transferts entre les sites ! La définition d’un lien WAN pourrait être la suivante: lien réseau disposant d’une bande passante limitée avec une latence non constante, voire hasardeuse, qui peut envoyer les paquets dans le désordre. Bref, tout pour mettre en péril les objectifs RPO/RTO. Le nouveau challenge consiste à prendre en compte la croissance ininterrompue des données, la criticité des applications et l’augmentation des distances entre les datacenters. Nous avons à l’esprit que la réplication génère un trafic soutenu en plus des éventuelles applications métiers.
Quelles solutions s’offrent à nous ? Deux. L’un consiste à optimiser les liaisons, l’autre d’implémenter des appliances d’accélérations WAN et/ou de déduplication. La plupart du temps, les DSI commandent des liens plus gros, sans mener des investigations préalables, et bien souvent ces nouveaux liens, loués très cher, ne solutionnent pas leur problème de performance ! Mais dans un premier temps, il est important de classifier les données et les applications par criticité, il est inutile d’avoir un RPO/RTO très faible pour une application ne servant qu’une fois par mois, tandis qu’une logiciel de facture ou CRM sera très important et impactant pour l’activité d’une entreprise. De plus, il convient d’analyser les moyens/protocoles employés, certaines technologies propriétaires ou reposant sur de l’encapsulation (FCIP, FCoE) peuvent affecter les performances d’une appliance du fait que les données soient déjà compressées, par exemple. Il est également important de connaître le trafic généré en moyenne, les pics et leur fréquences, combien est-il nécessaire pour transférer un élément ou son delta, …
Impacts sur la bande passante
Il existe deux principaux ennemis qui dégradent la bande passante, la latence et la perte de paquets (voir même la réception dans le désordre). L’oversubscription consiste pour un routeur a mettre en file d’attente des paquets (dans le désordre ou inutilisables) en évitant de les perdre et si possible sans dégrader les performances (cela dépend des capacités du routeur). Une retransmission excessive entraine une baisse du GOODPUT. Cette notion fait référence à de la bande passante utile et non théorique. Par exemple, une liaison 2 Mb ne délivre pas 2 Mb, mais peut-être 1.8 Mb, c’est ce que l’on appelle le GOODPUT (voir la définition ici et ici).
Imagine that a file is being transferred using HTTP over a switched Ethernet connection with a total channel capacity of 100 megabits per second. The file cannot be transferred over Ethernet as a single contiguous stream; instead, it must be broken down into individual chunks. These chunks must be no larger than the maximum transmission unit of Ethernet, which is 1500 bytes. Each packet requires 20 bytes of IP header information and 20 bytes of TCP header information, so only 1460 bytes are available per packet for the file transfer data itself (Unix systems, Linux, and Mac OS X are further limited to 1448 bytes as they also carry a 12 bytes time stamp[1]). Furthermore, the data are transmitted over Ethernet in a frame, which imposes a 26 byte overhead per packet. Given these overheads, the maximum goodput is 1460/1526 × 100 Mbit/s which is 95.67 megabits per second or 11.959 megabytes per second. Source: http://en.wikipedia.org/wiki/Goodput
Ce schéma montre bien l’impact des pertes des paquets sur le GOODPUT.
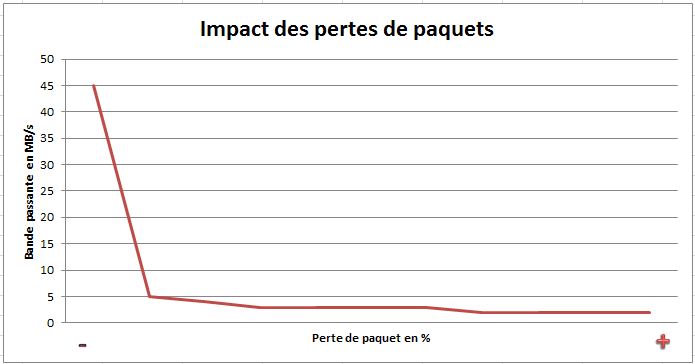
Il convient d’analyser tous vos flux et s’ils sont soumis à des règles de QoS ? Limiter les bandes passantes par flux de façon à assurer le service ou afin de se prémunir de la monopolisation d’une application au détriment d’une autre, demeure essentiel. La paramètre « latence » est également nécessaire d’être pris en compte car plus la distance est grande plus le chemin à parcourir pour les paquets est important ! (avec le risque de pertes, etc….)
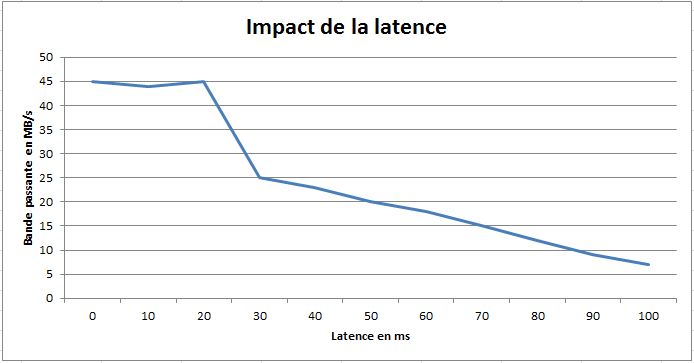
Afin de se prémunir de ce type de problèmes, il existe FEC (Forward Error Correfction), POC (Packet Order Correction), l’optimisation de la fenêtre TCP, etc… Ce lien détaille les différentes optimisations WAN possibles.
À titre d’exemple, augmenter la bande passante devient inopérant en cas de forte latence due à des distances trop importantes entre les équipements sources et cibles. De même, la bande passante importe peu si les paquets sont perdus ou fournis de manière non-séquencée compte tenu des phénomènes de congestion, comme c’est souvent le cas au sein des environnements Cloud et MPLS plus économiques, mais de moindre qualité.
Enfin, lorsque tous les facteurs sont considérés, le coût de l’ajout plus de bande passante est souvent nettement plus élevé que le coût du déploiement d’une solution d’accélération WAN. Mis à part une augmentation spectaculaire des dépenses de la bande passante récurrents (30% à 60% en moyenne),
Certaines appliances spécialisées dans l’optimisation comme SRDF/A EMC, Symmetrix Remote, Data Facility/Asynchronous FCIP, etc… promettent:
- Accélère de 5 à 50 fois les applications sur le WAN et même jusqu’à 100 fois dans certains cas
- Réduit de 65 à 95 % la congestion du réseau et l’utilisation de la bande passante du WAN
- Fournit des performances de type LAN aux employés mobiles du monde entier
Riverbed met à disposition un outil permettant de calculer les gains, disponible ici.
Plus le débit WAN est important, meilleur pourra être le RPO/RTO. En effet, la capacité à reprendre d’un site à l’autre et la capacité de sauvegarder le plus vite possible impactent directement la possibilité de mise en oeuvre d’une continuité d’activité et/ou de récupération après sinistre. La diminution de la perte de données maximale admissible (RPO) et la réduction de la durée maximale d’interruption admissible (RTO) s’opère en optimisant les WAN et les VPN.
Considérations liées au stockage
Certains dispositifs de stockage disposent de mécanismes qui leurs sont propres et dédiés à la réplication, comme la déduplication (très bon rendement), la compression, Packet Striping, … Cela peut apparaitre étonnant, mais il convient la plupart du temps de désactiver ces options qui peuvent rendre les algorithmes des appliances inopérants ou moins efficaces. Prenons l’exemple de la compression, en désactivant la fonctionnalité sur la baie, on déporte le calcul CPU vers l’appliance qui est spécialisée pour ce traitement. A noter qu’une appliance d’accélération WAN sera également incapable de traiter une encryption activée au niveau d’une baie. Voici le schéma a respecter:
OPTIMISER -> ENCRYPTER -> DECRYPTER -> DELIVRER
Pour une réplication synchrone, la latence est un facteur très important car les lectures s’effectuent en local mais les écritures sont envoyées vers la baie distante dont l’ acknowledgment est nécessaire !
Prenons le cas d’une fibre noire qui ne nous posera pas de problèmes particuliers jusqu’à 10km (1300nm laser) ou 35km (1550nm laser). On peut partir sur une perte de 5 μs par kilomètres. Une transaction iScsi typique traverse le lien 8 fois, soit 4 roundtrips. Ce qui équivaut donc à donc 5 μs * 35 kms * 8(trips)= 1400 μs soit 1.4 ms. Il faut avoir en tête que les connexions iSCSI longues distances (inter-site) qui traversent des équipements WAN ou de type FC avec IP (iFCP, FCIP, FCoE, …) alourdissent la latence !
Le cas CISCO WAAS / Veeam
Prenons l’exemple concret des apports de Cisco Wide Area Application Services. Cette technologie optimise les performances des applications basées sur TCP. Voici les données: sites reliés en 10 Mb MPLS avec 40 ms de latence (données CISCO/Veeam).
SANS WAAS:
Replica initial — 12.8GB transférés via WAN — Temps total: 3 heures 12min 17sec
Second Replica — 948MB transférés via WAN — Temps total: 23min 45sec
AVEC WAAS:
Replica initial — 4.8GB transférés via WAN — Temps total: 2 heures 22 minutes
Second Replica — 149MB transférés via WAN — Temps total: 11min 21sec
CONCLUSION:
Replica initial — Veeam a transféré 12.8GB, WAAS a optimisé de 4.8GB — Compression totale 62%
Second Replica — Veeam a transféré 901MB, WAAS a optimisé de 149MB — Compression totale 83%
Quelques liens complémentaires:
http://forums.veeam.com/viewtopic.php?f=2&t=2608&start=0#p10774
http://forums.veeam.com/viewtopic.php?f=2&t=2607#p15480
Témoignages
Je suis désolé de faire un peu de pub, mais ces témoignages me semblent tout à fait pertinent à propos d’un retour d’expérience.
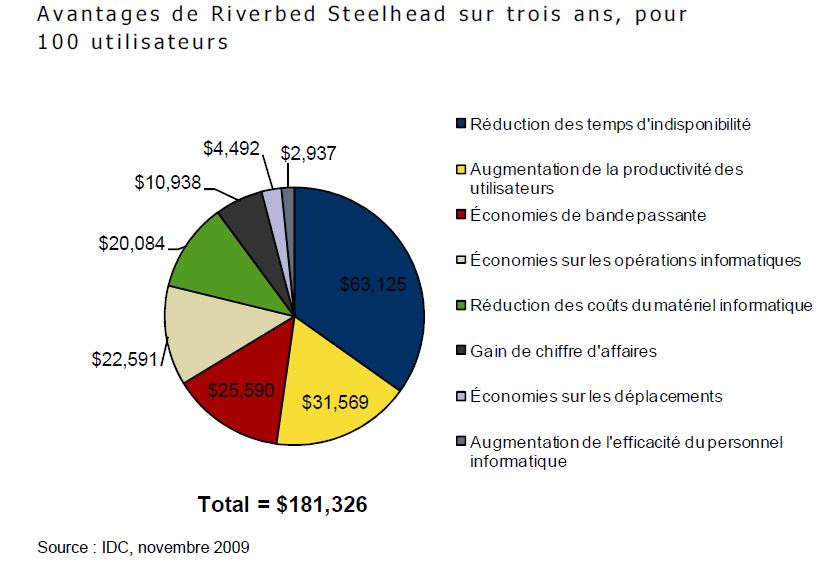
Avant, de nombreux clients pensaient que la seule solution adaptée à leur demande croissante était d’ajouter en permanence de la bande passante dans l’espoir de rester en phase avec les besoins de l’entreprise. Un client explique : « Lors du premier déploiement, notre utilisation de la bande passante a chuté. Nous avons pu renégocier nos contrats et nous allons économiser plus de 2 millions de dollars ces deux prochaines années ». En moyenne, les clients interrogés économisent 979 973 $ par an en coûts de bande passante depuis le déploiement de Riverbed Steelhead.
Concernant les bandes de sauvegarde, un client a déclaré : « Nous effectuons des sauvegardes à distance, ce que nous ne pouvions pas faire auparavant. Nous évitons l’utilisation de bandes et le coût de trois ou quatre lecteurs par site. » Certains clients réduisent le nombre de lecteurs de bandes dont ils ont besoin, tandis que d’autres les suppriment complètement : « Nous sommes sur le point d’éliminer tous nos lecteurs de bande et de centraliser nos sauvegardes », annonce un responsable. « Avant, lorsque nous transférions beaucoup de données, nous avions souvent trois ou quatre semaines de retard sur les sauvegardes. Mais depuis le déploiement de Riverbed, il est extrêmement rare que nous ayons plus d’un jour de retard ». Nos économies annuelles sur les bandes, les lecteurs de bande et les sauvegardes à distance sont en moyenne de 84 639 $.
Grandes fenêtres TCP (TCP Window Size)
C’est un paramètre important, voire même le plus important, pour maximiser la bande passante d’un réseau, la bande passante peut être doublée ! Prenons un exemple pour bien différencier les termes: le tuyau d’arrosage représente le lien, le diamètre représente la bande passante, la longueur du tuyau la latence (ou RTT Round Trip Time) et la fenêtre TCP définit la quantité d’eau (données) nécessaire pour remplir le tuyau.
Calcul de la fenêtre TCP optimale
Voici la formule pour calculer la fenêtre: ( bande passante * RTT ) / 8 / 1024 donc pour un lien 2 Mb/sec et 20 ms de latence => ( 2.000.000 * 0.02 ) / 8 / 1024 = 48 Kb – attention il faut convertir le ping exprimé en ms en sec !
Calcul du débit TCP
Pour calculer le débit, la formule suivante s’applique: Taille de la fenêtre en bits / latence en sec = débit en bits. Exemple d’une fenêtre de 64 Kb avec 30 ms de latence => 65536 * 8 / 0.030 => 17.4 Mbps
La taille de la fenêtre correspond au nombre maximal de paquets qui peut être envoyé sans attendre un accusé de réception positif. Les grandes fenêtres TCP améliorent les performances TCP/IP lorsque des quantités importantes de données transitent entre l’émetteur et le récepteur. Dans les communications TCP classiques, la taille maximale de la fenêtre est généralement fixée sur l’ensemble des connexions et limitée à 64 kilo-octets (65,535 octets). Donc si votre calcul renvoi à un fenêtre de 85 Kb sur un lien 4 Mb, la fenêtre par défaut (64 Kb) sous-utilisera le lien => 64/85 => 75% soit 3 Mb.
Avec une grande fenêtre, vous pouvez recalculer de manière dynamique et adapter la taille de la fenêtre réelle en utilisant une option TCP selon vos besoins au cours des sessions plus longues. Avec cette option, un plus grand nombre de paquets de données est en transit sur le réseau en une seule fois, ce qui augmente le débit.
Par défaut, les ordinateurs exécutant des systèmes d’exploitation Windows Server 2003 n’acceptent, pour l’option de grandes fenêtres TCP, que les requêtes émises par les clients des ordinateurs TCP1323Opts auxquels ils sont connectés. Les ordinateurs TCP1323Opts déposent des requêtes pour l’option de grandes fenêtres TCP au cours de la poignée de mains en trois temps. Si vous voulez que votre ordinateur fasse des demandes de grande fenêtre TCP, vous devez activer TCP1323Opts dans le Registre. Pour plus d’informations sur les grandes fenêtres TCP, voir la RFC 1323, « TCP Extensions for High Performance ».
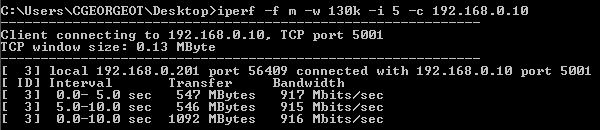
Vous pouvez vous amusez à tester les différentes fenêtre TCP à l’aide de l’outil iPerf. Cet outil permet de mesurer la performance d’un réseau entre 2 points. Le paramètre -w influe sur la taille de la fenêtre, dans un test passer de 60 à 130 donne un gain conséquent en passant de 5.2 à 15.7 Mb/s !
our appliquer une fenêtre TCP, la formule est le suivante: taille de la fenêtre en bits * 2 ^ facteur d’échelle – Donc pour fenêtre de 32 Ko avec un facteur 3 => 32768 * (2*2*2) = 262.144. Cette valeur sera à appliquer dans le registre HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\Tcpip\Parameters – TcpWindowSize.
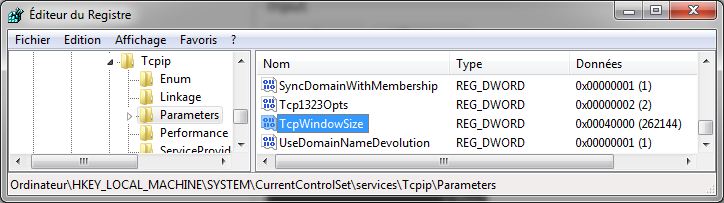
| Fenêtre TCP(RTT 70ms) |
Débit théoriqueen Mb/s |
Débit réalisteen Mb/s |
| 8 Kb | 0.9 | 0.8 |
| 16 Kb | 1.9 | 1.8 |
| 32 Kb | 3.7 | 2-3.5 |
| 64 Kb | 7.5 | 3-7 |
| 128 Kb | 15 | 6-14 |
| 256 Kb | 30 | 10-25 |
| 512 Kb | 60 | 20-40 |
| 1 Mb | 120 | 30-60 |
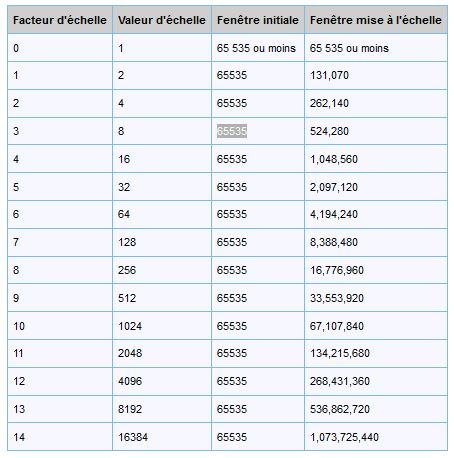
Le facteur d’échelle se trouve par le biais d’un analyse de trame et correspond à TCP: Window Scale Option – TCP: Option Type = Window Scale – TCP: Option Length = 3 (0×3) – TCP: Window Scale = 3 (0×3).
Plus d’informations ici.
Meilleure estimation RTT ou latence
TCP utilise le temps RTT pour faire une estimation de la durée nécessaire pour une communication de boucle entre un émetteur et un récepteur. Les serveurs fonctionnant sous Windows Server 2003 prennent en charge l’utilisation de l’option horodatage TCP de la RFC 1323 pour améliorer l’estimation RTT. En calculant plus souvent des informations RTT plus précises, TCP utilise de meilleures estimations pour définir la retransmission des temporisateurs, ce qui permet d’améliorer la vitesse et les performances TCP globales.
Les améliorations apportées à l’estimation RTT sont très utiles pour les liens plus longs de réseau en boucle, comme les réseaux étendus qui s’étendent sur les continents ou qui utilisent des liens de communication sans fil ou par satellite.
A noter que la taille de la fenêtre TCP est ajustée à quatre fois la taille MSS (MSS, Maximum Segment Size), jusqu’à une taille maximale de 64 K, à moins que l’option de mise à l’échelle de la fenêtre (RFC 1323) ne soit utilisée, d’où sont intérêt !
Par défaut, les ordinateurs exécutant des systèmes d’exploitation Windows Server 2003 n’acceptent, pour l’option horodatage TCP, que les requêtes émises par les clients des ordinateurs TCP1323Opts auxquels ils sont connectés. Les ordinateurs TCP1323Opts déposent des requêtes pour l’option horodatage TCP au cours de la poignée de mains en trois temps. Si vous voulez que votre ordinateur fasse des demandes d’horodatage TCP, vous devez activer TCP1323Opts dans le Registre. Pour plus d’informations sur l’horodatage TCP, voir la RFC 1323, « TCP Extensions for High Performance ».
Quelques exemples pratiques
Voici quelques liens et leur valeurs pratiques et théoriques. Généralement, on retire 30% pour obtenir une valeur réaliste.
| Type de lien | Mb/s | GB/h en théorie |
| T1 | 1.536 | 0.66 |
| LAN | 100 | 43.95 |
| OC3 | 155 | 68.12 |
Ce site est excellent, il permet de calculer les temps de transferts, etc… pour un débit => http://web.forret.com/tools/bandwidth.asp?speed=4&unit=Mbps
Prenons un exemple, vous devez sauvegarder 200 Go et vous disposez d’une liaison 4 Mbps. En théorie, cette liaison peut transmettre (théoriquement) 1.8 Go par heure, soit 200 / 1.8 = 111.11 heures pour transférer les données soit presque 5 jours ! Donc envoyer une cartouche de sauvegarde à l’autre bout du monde prendra moins et coûtera largement moins cher qu’acheter une liaison d’un débit plus important !
Prenons un autre exemple, 9 heures de travail génèrent 20 Go de données (ROC – Rate Of Change) et vous disposez d’une fenêtre de 24 heures – 9 heures de travail soit 15 heures disponibles pour réaliser la sauvegarde, soit au minimum 20 Go/ 15 heures = 1.33 Go/heure donc une ligne de 3 Mbps suffit pour atteindre l’objectif !
Il est important de connaitre le ROC et la fenêtre de sauvegarde disponible concernant les données à sauvegarder et/ou répliquer, bien entendu tout ceci est directement influencé par le RPO ! Il est donc très important de définir une criticité des applicatifs par ordre d’importance – critique: AD, DNS, CRM – important: Sharepoint, … – peu important: archive, … – Il convient également de faire attention au type de serveur à prendre en compte, un serveur Exchange représente, par exemple 2 partitions, une système et l’autre contenant les fichiers EDB, c’est à dire qu’il est nécessaire de sauvegarder régulièrement les EDB, et moins souvent le système, en excluant par exemple le SWAP, les temps, … Le cas de la VDI est plus complexe, car il faut sauvegarder les profiles, cache web, … Pour un serveur Oracle, une réplication du redo log peut s’avérer suffisant !
Conclusion
Pour conclure, la réplication de données inter-sites et les éventuelles problèmes de performances associés ne se résolvent pas uniquement en louant une liaison plus importante, il est important de:
- Définir un niveau de criticité des applications et données à protéger
- Analyser et réaliser un tuning TCP de vos liaisons
- Mettre en oeuvre des appliances d’accélération WAN
- Analyser, au niveau serveur, ce qu’il est nécessaire de sauvegarder
- Connaitre sa fenêtre de sauvegarde et son ROC (par application, ….)
- Dans le cadre de PRA (réplication de VM en asynchrone, …), prioriser les flux (QoS, …)
Quelques liens supplémentaires
Livre Windows Server® 2008 TCP/IP Protocols and Services
TCP/IP Registry Values for Microsoft Windows Vista and Windows Server 2008
New Networking Features in Windows Server 2008 and Windows Vista
Réglage automatique de la fenêtre de réception TCP