Voilà un sujet qui ouvre le débat: Quid de la fragmentation versus les stockages de type SAN ? Nous sommes tous d’accord sur le fait que les performances E/S peuvent être affectées de façon significative selon le niveau de fragmentation du système de fichiers, surtout lors d’accès séquentiels. Certains benchmarks parlent de 33% de perte de performances sur un RAID-1. Essayons d’y voir plus clair…
Le phénomène de fragmentation s’explique du fait qu’une requête I/O s’exécute sur plusieurs blocs répartis sur différentes endroits du disque, on parle de bloc non contigus. Le but de la défragmentation est de réduire le temps de « voyage » sur les plateaux du disque (positionnement, lecture, continuation de la requête). Prenons un exemple simple, vous devez chercher un dossier de 4 classeurs dans votre bureau qui comporte 10 armoires espacées l’une de l’autre de 5 mètres, la fragmentation s’expliquerait de la façon suivante, vos 4 classeurs sont répartis dans 4 armoires différentes, il va falloir du temps pour constituer l’ensemble de dossier… La défragmentation consisterait à ranger ces 4 classeurs dans une même armoire, les uns à côté des autres ![]() Le gain de temps est considérable !
Le gain de temps est considérable !
La taille de la mémoire cache des baies de stockage actuelles est telle que la fragmentation impacte peu les performances. Mais il faut savoir qu’une baie de stockage gère des blocs et est incapable de distinguer quelle I/O est relatif à telle donnée, et encore moins de répartir intelligemment les fragments sur la pile RAID, car la baie de stockage travaille avec de LUNs qui n’ont pas de rapport direct avec la géométrie des disques (plateaux, têtes, secteurs, …)
Un processus de défragmentation sur un disque local alourdit considérablement le travail du disque dur, sur une baie de stockage, cela va être encore pire ! Si vous décidez de défragmenter une partition située sur un RAID-5, tous les autres serveurs accédant à cette ressource seront pénalisés également. A noter que les logiciels de défragmentation agissent uniquement sur le système de fichier du serveur sur lesquel il est installé, et n’a même pas connaissance de quel autre serveur pourrait éventuellement être connecté sur le même LUN… La dégradation est performances peut être dramatique si la taille de la fragmentation est inférieure à la taille de stripe de votre RAID, car une I/O pourrait générer deux requêtes ! Première conclusion, une défragmentation doit être exécutée en dehors des plages de production !
La communauté est perplexe sur le fait qu’une défragmentation pourrait ou non avoir des effets positifs sur les performances. Pour ma part, je suis assez mitigé sur la question, un même RAID-5 pour être découpé en plusieurs LUNs que se partageraient le serveur, comment le processus de défragmentation serait capable de répartir les fragments d’un fichier sur plusieurs disques tout en tenant compte de la taille de stripe de la pile RAID, sachant que les contrôleurs des baies de stockage agissent au niveau bloc… Qui serait en mesure de prouver qu’une défragmentation assurait à coup sûr que les fragments serait répartis de façon optimale sur l’ensemble des disques d’une pile RAID ?
De même, la défragmentation sur les Pools de stockage virtuels ou volume Thin « Provisionné » serait inutile et non recommandé. Dans le premier cas, défragmenter un volume d’un pool contenant plusieurs RAID-10 n’apporterait rien car la couche physique et logique du système disque est complétement abstraite, elle est virtualisée, aucune corrélation entre les secteurs et les blocs ! De même que défragmenter un volume Thin « Provisionné » pourrait nuire à sa fonction première du fait que le processus allouerait inutilement des nouveaux secteurs !
J’amène une autre question sur le tapis: quid de l’Auto Tiering ? Certains algorithmes sont basés au niveau fichier, d’autre au niveau bloc, quoiqu’il en soit il ne faut pas défragmenter un type de volume, car une défragmentation pourrait promouvoir ou rétrograder une donnée inutilement. En principe les algorithmes font de la ré-allocation de façon intelligente et placent la donnée promue ou rétrogradée de façon optimale sur le système de disque approprié.
De la même façon, les volumes répliqués ne doivent pas être défragmentés, car une opération sur un site entraîne la même sur l’autre site en plus des opérations de production, idem pour les volume CDP, car les journaux pourraient « exploser » ainsi que pour la déduplication.
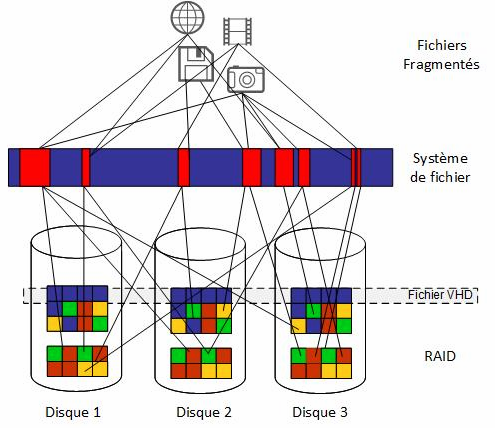
Le schéma ci-dessus nous montre plusieurs choses:
- Un fichier VHD est crée sur l’ensemble de la stripe composant la pile RAID, la fragmentation est donc faible, mais techniquement nous pourrions parler de fragmentation du fait qu’il est réparti sur plusieurs disque au lieu d’un seul, mais en environnement SAN/RAID, il est bien plus optimal de lire d’un coup un stripe dans son ensemble ! (augmentation des débits, IOPS, …)
- Par contre, défragmenter « l’intérieur » d’un fichier VHD présenterait de l’intérêt mais n’agit qu’au niveau du système de fichier de la VM
- ce que nous montre ce schéma, et montre bien qu’une défragmentation apporte peu de chose, c’est qu’une donnée fragmentée ou non au niveau du système de fichiers peut être répartie d’un point de vue physique n’importe où sur le RAID, qui dépend de taille de stripe, chunk, etc…
- Néanmoins nous sommes tous d’accord sur le fait qu’une défragmentation consomme moins de ressources…
Certaines solutions, Diskeeper, avancent que leur technologie prends en compte les fonctions avancées des SAN, j’en pas convaincu, Windows ne voit qu’un type de partition et sa taille, mais n’a aucune idée des caractéristiques physiques du disque (IDE, SCSI, RAID, SAN) ! Comment peut t’il savoir qu’un RAID-5 est découpé en plusieurs LUNs ? Est-ce que Windows, lorsqu’il lit un fichier WORD, sait qu’il se trouve sur 3 des 5 disques composants la pile RAID, NON… C’est pourtant leur promesse…
Pour conclure…
Les contrôleurs des baies de stockage ont déjà pour mission de répartir intelligemment et de façon optimale la localisation des blocs sur le système disque. De plus, la rapidité des disques (15.000 tours, SAS, NCQ, …), la taille des mémoire caches et autres optimisations gomment/diminuent les effets néfastes de la fragmentation.
En fait nous aurions 3 niveaux de fragmentation, à l’intérieur d’une VM, au niveau du VHD, et au niveau du RAID… Une défragmentation agirait beaucoup au niveau des blocs logiques sur l’ensemble des disques composant la pile RAID sans pour autant améliorer les performances, les blocs devant être accéder fréquemment pourraient être déplacés vers des secteurs lents.
L’idéal serait une solution qui ferait la corrélation entre les fichiers (logique) et les blocs au niveau SAN (physique). NetApp propose via sa commande reallocate de ré-allouer via un schedule les blocs !
La défragmentation est clairement nécessaire pour des systèmes DAS ou NAS, sachant que certaines technologies des éditeurs de solution de défragmentation jugent à la volée la rapidité des secteurs logiques avant de faire une ré-allocation des blocs… Pour le reste, j’estime que ce n’est pas nécessaire contrairement à tous les arguments marketing de certains éditeurs, à moins de me convaincre des points évoqués ci-dessus ![]()
Voici quelques éléments de réponse complémentaires concernant VMWARE, Hyper-V, et SQL.
Le cas Azure
Le cloud n’est pas épargné par ce phénomène, mais est plus compliqué à traiter du fait que l’on a pas accès à l’infrastructure de stockage. Néanmoins, il est possible de traiter la chose.
L’un des types de blob pris en charge par Windows Azure Storage est le Page BLOB. Les Page BLOB fournissent un stockage efficace des données éparses en stockant physiquement et uniquement les pages qui ont été écrites et non effacées. Chaque page a une taille de 512 octets. L’appel de service Get PAge Ranges REST renvoie une liste de toutes les plages de pages contiguës qui contiennent des données valides. Cela peut échouer dans certaines circonstances lorsque le service prend trop de temps pour traiter la demande. Comme toutes les API REST Blob, Get Page Ranges prend un paramètre timeout qui spécifie l’heure à laquelle une requête est autorisée, y compris la lecture / écriture sur le réseau.
Dans un Page BLOB très fragmenté avec un grand nombre d’écritures, le remplissage de la liste renvoyée par Get Page Ranges peut prendre plus de temps que le délai d’expiration du serveur et par conséquent la demande échouera. Par conséquent, il est recommandé que si votre modèle d’utilisation d’application comporte des Page BLOB avec un grand nombre d’écritures et que vous souhaitiez appeler GetPageRanges, votre application doit récupérer un sous-ensemble des plages de pages à la fois.
Par exemple, supposons qu’un objet BLOB de 500 Go ait été rempli avec 500 000 écritures dans le blob. Par défaut, le client de stockage spécifie un délai de 90 secondes pour l’opération GetPageRanges. Si l’option GetPageRanges ne se termine pas dans l’intervalle de délai d’expiration du serveur, l’appel échoue. Cela peut être résolu en récupérant les plages par groupes de, disons, 50 Go. Cela divise le travail en dix demandes. Chacune de ces requêtes se terminerait alors individuellement dans l’intervalle de temporisation du serveur, permettant à toutes les plages d’être récupérées avec succès.
Pour être certain que les requêtes se terminent dans l’intervalle de délai d’expiration du serveur, l’exploration s’étend sur des segments de 150 Mo chacun. C’est sûr, même pour les Page BLOB au maximum fragmenté. Si un blob de page est moins fragmenté, des segments plus grands peuvent être utilisés.
Les block blob vous permettent de traiter de gros blobs efficacement. Les block blob sont constitués de blocs, dont chacun est identifié par un ID de bloc. Vous créez ou modifiez un block blob en écrivant un ensemble de blocs et en les validant par leur ID de bloc. Chaque bloc peut avoir une taille différente, jusqu’à un maximum de 100 Mo (4 Mo pour les demandes utilisant des versions REST avant le mai 2016), et un block blob peut inclure jusqu’à 50 000 blocs. La taille maximale d’un block blob est donc légèrement supérieure à 4,75 To (100 Mo X 50 000 blocs). Pour les versions REST avant le mai 2016, la taille maximale d’un block blob est un peu plus de 195 Go (4 Mo X 50 000 blocs). Si vous écrivez un block blob ne dépassant pas 256 Mo (64 Mo pour les demandes utilisant des versions REST antérieures à mai 2016), vous pouvez le télécharger intégralement avec une seule opération d’écriture avec Put Blob.
Les clients de stockage utilisent par défaut un téléchargement de bloc unique de 32 Mo maximum, paramétrable à l’aide de la propriété SingleBlobUploadThresholdInBytes. Lorsqu’un transfert de blocs BLOB est plus grand que la valeur de cette propriété, les clients de stockage décomposent le fichier en blocs. Vous pouvez définir le nombre de threads utilisés pour télécharger les blocs en parallèle à l’aide de la propriété ParallelOperationThreadCount.
C’est assez technique, et vous trouverez des ressources ici:
- https://blogs.msdn.microsoft.com/windowsazurestorage/2012/03/26/getting-the-page-ranges-of-a-large-page-blob-in-segments/
- https://www.microsoft.com/en-us/research/publication/to-blob-or-not-to-blob-large-object-storage-in-a-database-or-a-filesystem/
- https://docs.microsoft.com/en-us/rest/api/storageservices/understanding-block-blobs–append-blobs–and-page-blobs