N’importe quelle entreprise a un jour réfléchi sur les conséquences d’un arrêt de production et les coûts qui en découleraient. Certaines d’entre elles pourraient se permettre un arrêt de production de trente minute tandis que d’autre ne pourraient pas se permettent de prendre plus de deux heures de données.
De ces exigences ont émergé des termes appelés Plan de Reprise d’Activité (PRA) ou de continuité d’activité (PCA) qui sont intimement associés aux notions de RTO (Recovery Time Objective) et RPO (Recovery Point Objective). La première notion correspond à un temps maximal pour reprendre l’activité tandis que la deuxième exprime le delta temps entre la perte maximale de données tolérée au moment du sinistre et au moment où l’activité redémarre, soit la perte de données maximale acceptable.
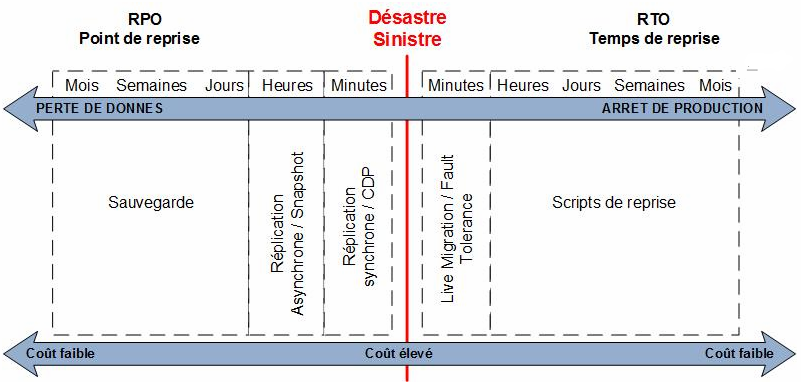
Bien entendu, la situation rêvée de n’importe quelle entreprise est d’avoir une valeur la plus proche possible du zéro pour le RTO et le RPO. Plus la valeur désirée est proche du zéro, plus les coûts associés seront élevés. En fonction des valeurs désirées, le schéma suivant vous indiquera les moyens à mettre en œuvre.
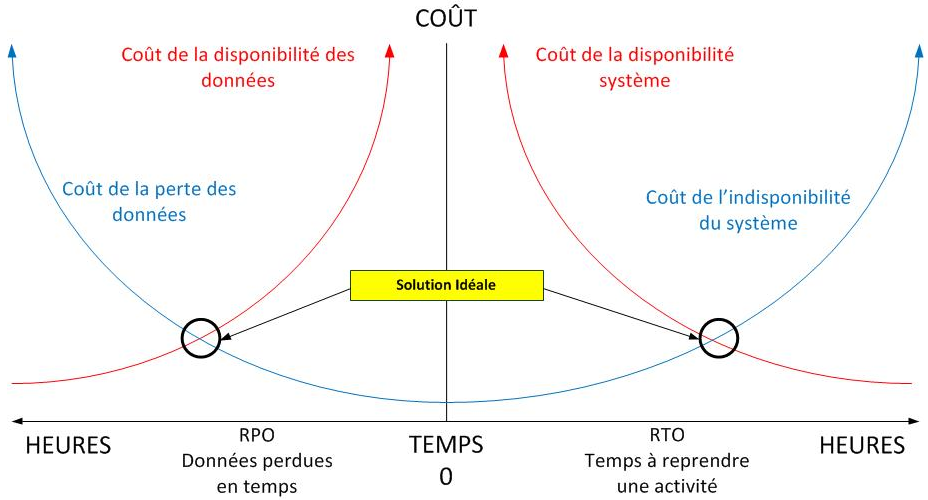
Il existe plusieurs sinistres comme par exemple la panne d’un serveur, d’un commutateur de stockage, d’une baie ou pire, d’un site complet. Il convient dès la conception de votre infrastructure de définir la disponibilité de vos données qui conditionneront directement le budget à consacrer : achat d’un serveur doté d’alimentations redondantes, double contrôleur pour une baie de stockage, licence de virtualisation permettant le déplacement à chaud d’une machine virtuelle, etc…
Seulement la redondance des éléments physiques d’un serveur ou d’une baie permettent uniquement une certaine continuité (PCA) malgré un sinistre mais ne permettent pas de se prémunir d’un virus ou d’une corruption de données.
Commencez par identifier les services qui nécessitent la mise en œuvre de tels moyens. Un serveur de développement n’est pas une application critique et il serait totalement marginal de protéger ce service au même titre qu’un ERP.
Une valeur RTO proche de zéro nous indique qu’une solution de cluster ou de basculement automatique à chaud de machines virtuelles est certainement en place. Si la valeur s’en éloigne, une stratégie de PRA est certainement mise en application (procédure de restauration d’une sauvegarde, de remise en production de serveurs, …)
Une valeur RPO proche de zéro nous indique que la perte de données n’est pas acceptable, et qu’il convient donc de répliquer les données de façon synchrone. Plus on s’éloigne de la valeur zéro, on imagine que l’entreprise a déployé une réplication asynchrone (ordre de grandeur de 15 minutes par exemple) où une stratégie de sauvegarde lui correspondant qui peut s’exprimer en heures.
Grâce à des mécanismes RAID, de double alimentations, etc… les données sont sécurisées mais ne sont pas redondées ! En fonction des exigences, la réplication répond à des problématiques de redondance des données en maintenant l’accès à des données consistantes sur plusieurs sites, mais ne répond pas à des problématiques de corruption de données ! En effet, une corruption qui survient sur une base de données sera répliquée sur l’autre baie de stockage.
La réplication existe sous forme synchrone et asynchrone, la première forme nécessite des prérequis lourds mais permet d’obtenir un RTO et RPO proche de zéro du fait de la réplication en temps réel des donnés. En revanche, la réplication asynchrone permet d’obtenir un RTO / RPO variable en fonction des besoins, comme une reprise après sinistre par exemple.
Réplication synchrone
La réplication synchrone garantit une correspondance parfaite à tout moment des données répliquées entre la source et la cible. Néanmoins, elle exige un débit important et garanti car, contrairement à la réplication asynchrone, elle attend l’acquittement de l’écriture avant de rendre la main. Pour cette raison, des liens dédiés sont fortement recommandés. Par exemple, certains constructeurs recommandent au minimum une fibre de 8 Gb !
La réplication synchrone ne rend la main qu’après avoir validé l’acquittement d’une opération d’écriture. Ainsi, si votre liaison subit un engorgement ou est faible, la synchronisation impactera les performances du stockage de façon très importante, avec pour conséquences des TimeOut au niveau des serveurs, entre autres. C’est pour cette raison, que les distances entre les sites à répliquer ne sont pas aussi éloignés qu’ils peuvent l’être avec une réplication de type asynchrone.
La réplication synchrone étant coûteuse à déployer, il est possible de réfléchir à des scénarios permettant de mixer les différentes réplications et technologies de sécurisation des données.
Prenons l’exemple d’un serveur SQL dont le système est installé sur un volume A et les données sur un volume B. Le système d’exploitation n’étant mis à jour qu’assez rarement, il est envisageable de répliquer les données de façon synchrone et le système de façon asynchrone.
Des stratégies peuvent être mises en œuvre pour limiter au maximum la bande que pourrait consommer une réplication. Par exemple, pour une base de données Oracle, ne répliquer que les Redo Logs serait une solution.
Réplication asynchrone
La réplication asynchrone transmet les données à intervalle régulier en s’accommodant d’une bande passante faible et demeure la solution idéale pour mettre en œuvre un PRA (Plan de Reprise d’Activité) sur un site distant.
Contrairement à la réplication synchrone, celle-ci n’attends pas l’acquittement pour rendre la main. Ainsi, l’augmentation du trafic ou la chute du débit de la ligne de la réplication n’entraîne pas une baisse des performances.
Ainsi, il est tout à fait imaginable d’utiliser des stockages de performances différentes: un ERP sur le site principal sera hébergé sur des disques de type SAS tandis que le site secondaire hébergera le réplica de l’ERP sur des disques SATA.
Réplication asynchrone « temps réel »
Ce type de réplication est disponible selon les constructeurs de stockage. Cette réplication bénéficie du faible besoin en bande passante et de ses éventuelles fluctuations mais garantit également l’intégrité des données répliquées entre la source et la cible. Ce type de réplication est le plus souvent propriétaire et ne repose pas sur des mécanismes de groupe de consistance (IBM, Net APP, …) ou de snapshot qui peuvent faire chuter les performances.
Pour résumer, cette réplication présente sur le papier les avantages des réplications synchrones et asynchrones, à savoir réplica quasi temps réel et la bande passante requise est faible.
La reprise après sinistre
La reprise après sinistre s’associe à la notion de PRA et de RTO, c’est-à-dire que l’on prend en compte le pire des scénarios, la perte complète d’une salle serveurs (on parle aussi de Disaster Recovery).
Typiquement, un PRA s’associe à une réplication asynchrone tandis qu’une réplication synchrone, donc continue, s’applique à un PCA car on continue à produire malgré la perte d’un élément important de l’infrastructure.
La reprise après sinistre n’engage pas que les services informatiques d’une entreprise mais l’ensemble des services. En effet, l’entreprise ayant prévu l’incendie d’un site, ce sont les moyens de productions (machines-outils par exemple) qui représente l’activité commerciale, mais également l’outil informatique qui sert à produire des factures, qui seraient totalement détruits.
Un PRA est un plan d’urgence résultant d’une réflexion globale de l’entreprise visant à reprendre au plus vite une activité de production commerciale.
Mettre en œuvre un PCA demeure beaucoup plus onéreux qu’un PRA qui peut se permettre de remettre en production le minimum vital pour une entreprise, tandis que le PCA exige une transparence totale pour les utilisateurs en cas de sinistre. Ainsi, un plan de continuité d’activité nécessite d’acquérir le même matériel sur l’ensemble des sites pour garantir une cohérence de productivité.
Une entreprise plus modeste mettra en œuvre un plan de reprise d’activité. Par exemple, une entreprise dispose de quatre serveurs : un serveur pour la production, un pour les archives, un pour la vidéosurveillance et un dernier pour le site internet vitrine. Si un sinistre survient, il sera nécessaire de remettre en production le plus rapidement possible le serveur de production afin de pouvoir continuer à livrer et donc facturer.
Des outils spécifiques tels VMware SRM (Site Recovery Manager) ou DoubleTake permettent de simplifier la mise en place d’un plan de reprise d’activité. Ils permettent de simplifier, d’automatiser le basculement des applications critiques vers un site de secours.
Hyper-V Replica est une fonctionnalité destinée à vous aider dans la mise en oeuvre d’un plan de reprise d’activité grâce à la réplication de machines virtuelles sur un environnement de secours.
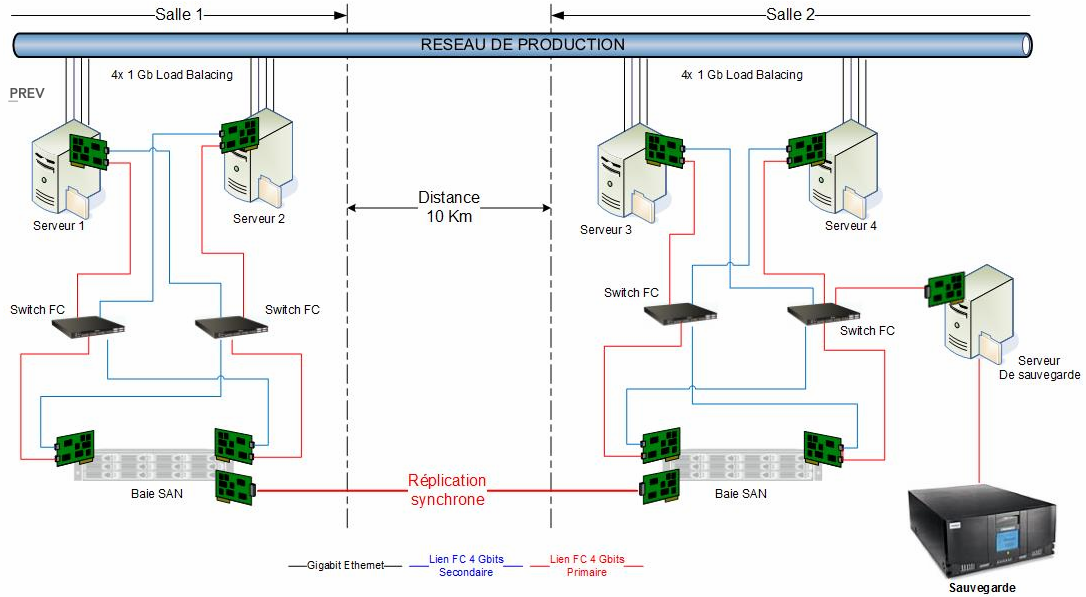
Le schéma suivant illustre parfaitement un PCA sur deux sites. Ils sont strictement identiques, disposent de commutateurs redondants, de doubles contrôleurs au niveau du stockage, les données se répliquent de façon synchrone et la sauvegarde est externalisée sur l’un des sites. Le défaut majeur de cette architecture réside dans le fait qu’il n’existe qu’une seule baie de stockage pouvant mettre à mal la continuité d’activité, on parle ici de SPOF (Single Point Of Failure – point unique de défaillance).
Les applications Cloud
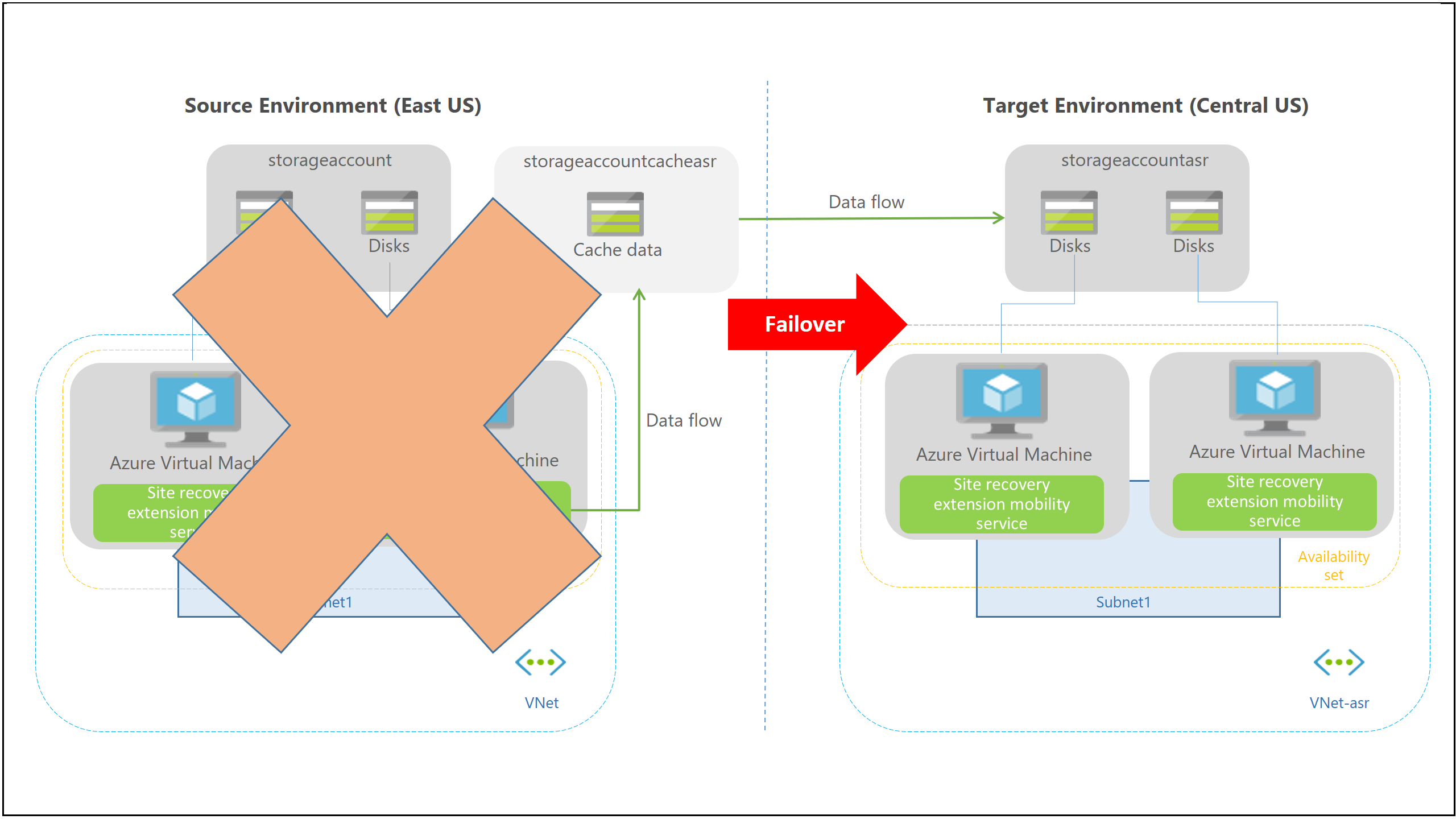
Azure Site Recovery permet d’assurer la continuité de l’activité en maintenant l’exécution des charges de travail et applications métier lors des interruptions. Site Recovery réplique les charges de travail s’exécutant sur des machines virtuelles et physiques depuis un site principal vers un emplacement secondaire. En cas d’interruption au niveau de votre site principal, vous basculez vers l’emplacement secondaire, depuis lequel vous pouvez accéder aux applications. Quand l’emplacement principal est de nouveau fonctionnel, vous pouvez effectuer une restauration automatique vers celui-ci.
Site Recovery est très intéressant car il permet de sécuriser des serveurs physiques, de l’Hyper-V, VMware, Azure vers Azure, et ce à un coût vraiment modique.
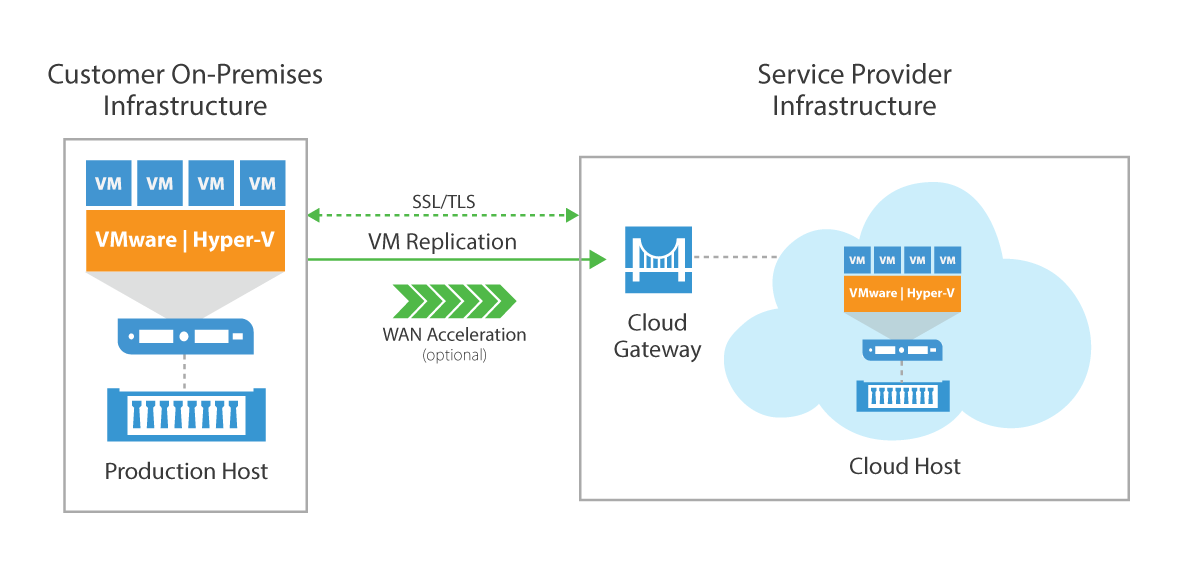
Veeam Cloud Connect DRaaS permet une reprise d’activité basée sur le cloud entièrement intégrée, rapide et sécurisée. Elle comprend notamment :
- un hôte cloud pour la reprise d’activité avec CPU (unité centrale), RAM (mémoire à accès aléatoire), stockage et ressources réseau allouées par un fournisseur de DRaaS
- le basculement de site complet vers un site de reprise d’activité distant depuis n’importe où et en quelques clics au moyen d’un portail Web sécurisé et basculement de site partiel pour basculer instantanément sur les réplicas de VMs sélectionnés
- le retour après basculement complet et partiel pour revenir à votre exploitation normale
- les appliances d’extension réseau intégrées pour simplifier la complexité de la mise en réseau et préserver la communication vers et entre les VMs en exécution, indépendamment de leur emplacement physique
- l’orchestration du basculement en 1 clic pour une exécution rapide et le test de basculement pour simuler un basculement sans perturber la production
- une connectivité sur un port unique par l’intermédiaire d’une connexion TLS/SSL (Transport Layer Security/Secure Sockets Layer) fiable et sécurisée vers un fournisseur de services avec chiffrement du trafic
- plusieurs technologies de réduction de trafic, dont l’accélération WAN intégrée et le seeding des réplicas
- le choix simple d’un fournisseur de services Veeam et avec pointage de vos tâches de réplication vers l’hôte cloud que le fournisseur de DRaaS vous indiquera
 Bien entendu, il existe bien d’autres solutions, mais celles-ci méritent amplement d’être mises en avant, tant sur la simplicité ou sur des aspects financiers et/ou techniques.
Bien entendu, il existe bien d’autres solutions, mais celles-ci méritent amplement d’être mises en avant, tant sur la simplicité ou sur des aspects financiers et/ou techniques.